
January has been a busy month for the Viper team; involving website updates, filming a video, our first Viper user forum and HPC updates.
Over the holiday period Viper ticked over 7 million research core hours, the research community has reached this level in just 7 months since installation highlighting the amazing uptake.
The Viper website has been given a minor revamp to improve navigation and increase the amount of information for new and prospective Viper users.
The whole team have been involved in the shooting of a video highlighting Viper for the UCISA conference in March; the team were camera shy at first, but once relaxed really enjoyed the experience and are now eagerly waiting to see the finished video.
Over the holiday period, Viper received numerous software updates to improve stability, security and increase performance, one of these updates was to the Omnipath Interconnect.
The team organised and attended the first Viper user forum this month. The forum provided the opportunity to introduce ourselves to the wider Viper community, inform of current activity and updates undertaken and to explain the services we offer users such as teaching and software development. The user community also had the opportunity to pose questions to the Viper team, such as, is the user base growing?
Recently, as mentioned in the last post, a user having issues running Ansys Fluent on Viper contacted me for help
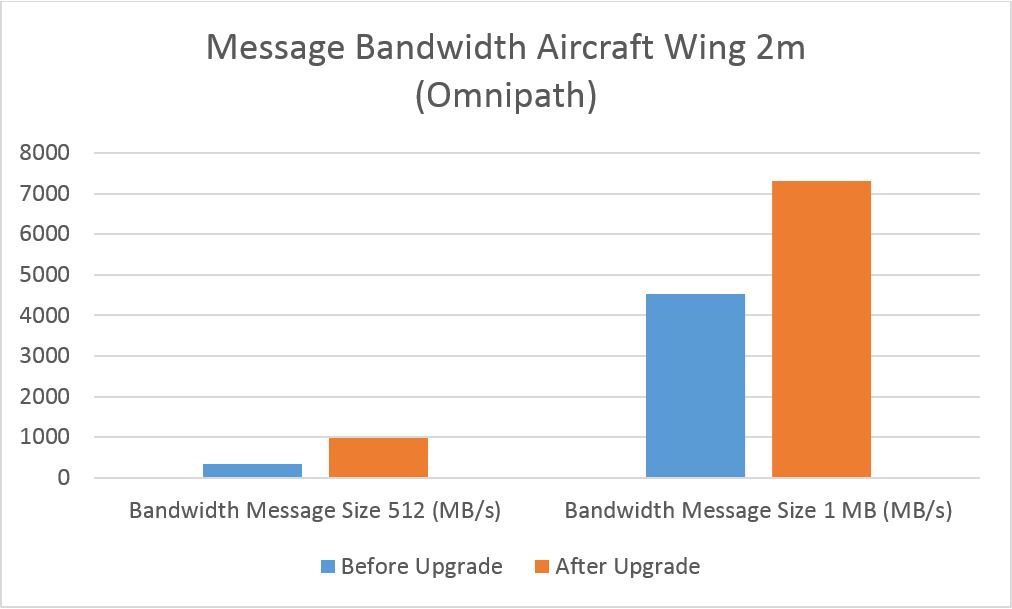
Before performing the Omnipath update and applying a ‘fix’, I took some benchmarks of a ‘real’ fluent job and the Ansys Fluent Aircraft Wing 2m benchmark. I also benchmarked running the same jobs on over Ethernet to find out the difference in performance.
Aircraft Wing 2m Benchmark before Upgrade (4 Nodes CPUS 56)
| Total Wall Time (s) | Solver Rating | Bandwidth Message Size 512 (MB/s) | Bandwidth Message Size 1 MB (MB/s) | Latency (ms) |
| 23.20 | 3744.3 | 347 | 4528 | 2.78 |
Aircraft Wing 2m Benchmark post Upgrade (4 Nodes CPUS 56)
| Total Wall Time (s) | Solver Rating | Bandwidth Message Size 512 (MB/s) | Bandwidth Message Size 1 MB (MB/s) | Latency (ms) |
| 9.70 | 9000 | 989 | 7301 | 1.20 |
The results show a huge difference between before and after, with a massive decrease in total wall time, finishing 13.5 seconds faster than before. The solver rating is the primary metric used to report performance results of fluent, with a 140% percent increase over the pre-upgrade, also shown is a 61% increase (1MB Message Size) in bandwidth over the Omnipath interconnect and a 1.58ms reduction in latency.
When running a ‘real’ fluent job the improvements are not as substantial as the benchmark.
‘Real’ Fluent job before Upgrade (10 Nodes CPUs 280)
| Nodes | NCPUS | Time (H:M:S) | MPI | Fabric |
| 10 | 280 | 04:11:09 | Intel | Omnipath |
‘Real’ Fluent job after Upgrade (10 Nodes CPUs 280)
| Nodes | NCPUS | Time (H:M:S) | MPI | Fabric |
| 10 | 280 | 02:42:11 | Intel | Omnipath |
After the update, the job finished 1hr 28min faster than before showing 35% increase in performance.
After the Omnipath update I also benchmarked the difference between Omnipath and Ethernet.
Aircraft Wing 2m Benchmark Omnipath (4 Nodes CPUS 56)
| Total Wall Time (s) | Solver Rating | Bandwidth Message Size 512 (MB/s) | Bandwidth Message Size 1 MB (MB/s) | Latency (ms) |
| 9.70 | 9000 | 989 | 7301 | 1.20 |
Aircraft Wing 2m Benchmark Ethernet (4 Nodes CPUS 56)
| Total Wall Time (s) | Solver Rating | Bandwidth Message Size 512 (MB/s) | Bandwidth Message Size 1 MB (MB/s) | Latency (ms) |
| 14.77 | 5849.7 | 107 | 110 | 24.51 |
This illustrates the significant improvements the Omnipath interconnect provides over Ethernet and shows the significant increases in bandwidth 7191 MB/s (1MB Message Size) and a 23.31ms reduction in latency.
The improvements seen in Ansys Fluent correlate with other benchmarks (to varying levels) run on different applications by my colleagues and researchers such as NWChem.
Next month there will be news about the wiki we have begun working on.